


A promessa é simples: respostas certas, na hora certa, usando o seu acervo interno, o caminho para isso passa por RAG (Retrieval Augmented Generation).
Uma abordagem que combina busca em bases próprias com modelos de linguagem.
O resultado é um copiloto que consulta documentos, políticas, tickets e repositórios antes de responder, reduzindo alucinações e aumentando a confiança.
Neste guia direto, você vai entender onde o RAG faz diferença, a arquitetura mínima para sair do zero, como avaliar qualidade e custo, além de um roadmap de 30 dias para validar no seu time.
O que é RAG e onde usar
RAG é um pipeline onde o modelo só responde depois de recuperar trechos relevantes do seu conteúdo.
O fluxo é: usuário pergunta.
O sistema busca os melhores pedaços em um índice.
Esses trechos viram contexto no prompt.
O modelo então responde citando as fontes.
Use quando o conhecimento necessário está em:
- Base de ajuda e manuais de produto.
- Contratos e documentos jurídicos.
- Procedimentos internos e playbooks de operação.
- Histórico de tickets e chats com clientes.
- Wikis e repositórios técnicos.
Evite quando a pergunta exige raciocínio puramente geral ou não há base confiável.
RAG multiplica a qualidade do que você já tem.
Se sua base for ruim, a resposta também será.
Arquitetura mínima viável

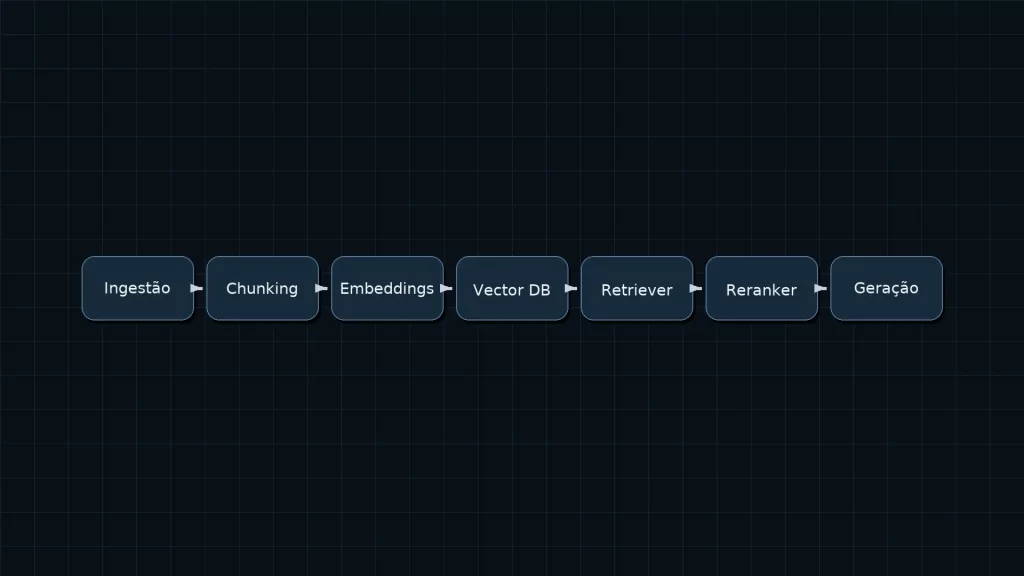
A arquitetura de um RAG funcional cabe em cinco blocos: ingestão, chunking, embeddings e indexação, recuperação com reordenação e geração com formatação.
Ingestão e preparação
Conecte as fontes com connectors simples. Comece por PDFs, páginas HTML, Markdown, planilhas e bancos de tickets.
Trate o básico:
- Normalização de caracteres e remoção de boilerplate.
- Deduplicação por checksum.
- Detecção de PII para redigir dados sensíveis quando necessário.
- Versionamento para rastrear o documento de origem.
Capture metadados desde o início: título, autor, data, tipo, permissões, link de origem e hash.
Eles serão úteis para filtros, relevância e auditoria.
Chunking: quebrar bem é metade do jogo
Evite pedaços gigantes, o ideal é trabalhar com 200 a 500 tokens por chunk, com sobreposição de 10 a 20% para preservar contexto.
Quando possível, use semantic chunking em títulos e subtítulos.
Em bases com muitos tópicos curtos, fixed-size resolve bem.
Embeddings e base vetorial
Embeddings transformam texto em vetores.
Escolha um modelo:
- Multilíngue se sua base estiver em mais de um idioma.
- Dimensões moderadas para equilibrar custo e precisão.
- Atualização periódica quando trocar de versão do modelo.
Para o índice, comece com um HNSW ou IVF bem parametrizado.
Decida entre:
- Gerenciado se você quer velocidade de implementação e SLAs.
- Self-hosted se precisar de controle fino, custo previsível e dados on-premises.
Recuperação e orquestração
Configure o retriever com top-k entre 3 e 8. Use busca híbrida combinando semântica com termo exato.
Em consultas amplas, ative MMR para diversidade.
Aplique um reranker sobre os 20 a 50 melhores resultados e devolva só os 3 a 5 finais para o modelo.
Na geração, siga um prompt template com instruções claras:
- Responder apenas com base nas fontes.
- Citar origem de cada trecho com metadados.
- Assumir “não sei” quando não houver evidência.
- Formatar resposta de forma funcional ao usuário.
Pós-processamento e entrega
Implemente citações com título e data, aplique filtros para remover redundância.
Se o caso exigir, adicione ferramentas como calculadora, pesquisa interna ou consultas SQL.
Para chats longos, guarde memória resumida para não estourar a janela de contexto.
Avaliação e métricas que importam
Medir é obrigatório, crie um conjunto de perguntas de verdade do seu negócio com respostas gabaritadas.
Monitore:
- Factualidade por amostra humana ou LLM-as-judge com rubrica.
- Coverage. Percentual de perguntas respondidas com base documental.
- Precision@k e Recall@k do retriever.
- Citações corretas por resposta.
- Tempo de resposta P95 e taxa de erro.
- Custo por resposta e custo por sessão.
- Deflection rate. Percentual de tickets evitados.
Teste em duas frentes:
- Offline. Avals automatizados com golden set.
- Online. Experimentos A/B medindo satisfação, cliques nas fontes e reabertura de tickets.
Segurança e governança desde o dia 1
RAG sem governança vira risco, trate como produto crítico:
- Permissões no índice. Filtro por usuário ou grupo no momento da busca. ABAC ou RBAC.
- Mascaramento de PII e dados sensíveis conforme política.
- Auditoria. Logue perguntas, fontes usadas, custos e quem acessou o quê.
- Residência de dados e retenção alinhadas a compliance.
- Gestão de segredos e rotação de chaves.
- Rate limiting e contenção de abuso.
Roadmap de 30 dias para POC
Semana 1. Escopo e baseline
Defina 3 casos de uso.
Separe 200 a 500 documentos de qualidade.
Monte um golden set com 50 perguntas.
Implemente telemetria de tempo e custo.
Semana 2. Pipeline e índice
Construa ingestão, chunking e embeddings.
Suba o índice vetorial.
Entregue um retriever híbrido com filtros por metadado.
Calibre top-k e MMR.
Semana 3. Orquestração e evals
Crie prompt template com regras de citação e abstain.
Adicione reranker.
Rode evals offline e ajuste parâmetros.
Estabeleça critérios de “go” para piloto.
Semana 4. Guardrails e piloto
Implemente permissões no índice, logs e painel de métricas.
Treine o time de operação.
Libere para um grupo de usuários e colete feedback estruturado.
Stack sugerida para começar bem
- LLM. API de uso geral ou modelo aberto afinado para raciocínio.
- Embeddings. Multilíngue e estável. Ponto de atenção em custos.
- Vector DB. Serviço gerenciado para POC. Avalie self-host quando estabilizar.
- Orquestração. Biblioteca madura para retrieval, reranking e tracing.
- Observabilidade. Painel de latência, custos e qualidade por intenção.
- Segurança. Controle de acesso no momento da busca e mascaramento de PII.
Evite travar o projeto escolhendo tudo de uma vez, priorize tempo de valor e padrões fáceis de manter.
Anti-padrões que derrubam a qualidade
- Chunks gigantes que diluem relevância.
- Só semântica sem busca lexical. Você perde precisão em nomes e códigos.
- Sem metadado. Fica impossível auditar e filtrar.
- Índice sem permissão. Vazamento em um clique.
- Sem evals. Ajustes viram opinião.
- Prompt que não permite “não sei”. Força alucinação.
- Não atualizar embeddings após mudanças no conteúdo.
Checklist rápido de implementação
- Fontes mapeadas e priorizadas
- Ingestão com normalização e deduplicação
- Chunking 200 a 500 tokens com sobreposição
- Embeddings multilíngue definidos
- Índice vetorial com busca híbrida e MMR
- Reranker ativado
- Prompt com regras de citação e abstain
- Permissões por usuário ou grupo
- Evals offline com golden set
- Painel com factualidade, P95 e custo por resposta
RAG não é moda
É um padrão de arquitetura para transformar seu conteúdo em respostas confiáveis.
O segredo está menos no modelo e mais na qualidade do índice, no chunking bem feito, nos metadados certos e na disciplina de medir.
Com um POC de 30 dias, você valida impacto em satisfação, tempo de atendimento e deflection, com segurança e governança desde o início.
A partir daí, o copiloto vira parte do seu produto.
Referências
- Guia prático de RAG e retrieval em documentação de frameworks de orquestração
- Documentações de bases vetoriais sobre HNSW e MMR
- Pesquisas sobre reranking e avaliação automatizada com LLM-as-judge
- Materiais de boas práticas de privacidade e PII em pipelines de IA
- Publicações de engenharia sobre observabilidade e métricas de qualidade em IA

